
Repository
https://github.com/pandas-dev/pandas
New Default & Bug Fix
Pandas is a data analysis library in Python. It excels at handling tabular data... sort of like Excel for programmers. It's in the top three most popular data science packages for Python, currently with 15,000 stars and 17,500 commits.
One common task in Pandas is saving dataframes (i.e. tables) as files. There are a variety of formats that can be used to serialize tables such as CSV, TSV, JSON, and pickle. Oftentimes, the files can be quite large (if they contain lots of data). Hence, users often want to compress output files for storage on disk. Pandas supports the Big Four compression protocols: gzip, xz, bzip2, and zip.
Recently, another contributor added a compression='infer' to several of the write methods, which infers compression from filename extensions. This enabled the following:
# path-to-file.csv.xz will be xz compressed
dataframe.to_csv('path-to-file.csv.xz', compression='infer')
# Previously, one had to explicitly specify the compression
dataframe.to_csv('path-to-file.csv.xz', compression='xz')
However, much of the convenience of inferring compression is lost if the user has to go out of their way to specify inference. Therefore, I opened the issue pandas-dev/pandas#22004 proposing to change the default for the compression argument from None to 'infer'. I was expecting my proposal to be a bit controversial, because it broke backwards compatibility. However, a maintainer quickly seconded the proposal:
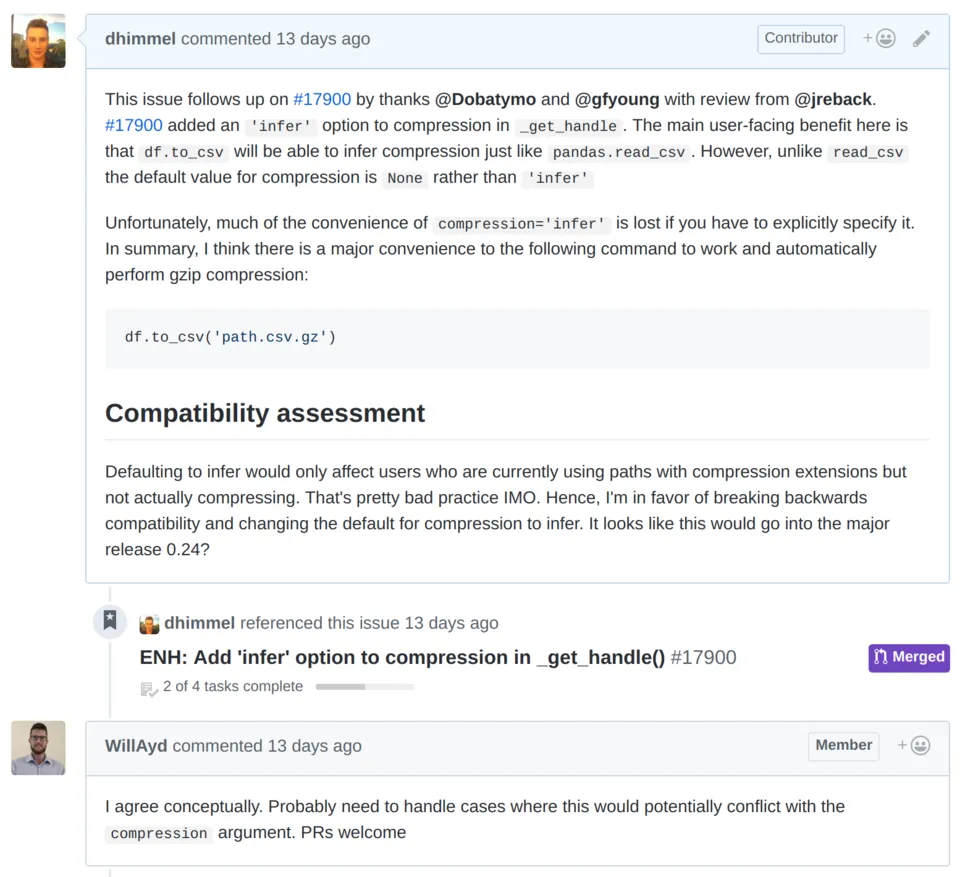
So I opened the pull request pandas-dev/pandas#22011 to switch the default value for compression to infer, which I titled "Default to_* methods to compression='infer'". The first commit, which implemented the bulk of the enhancement, was simple:
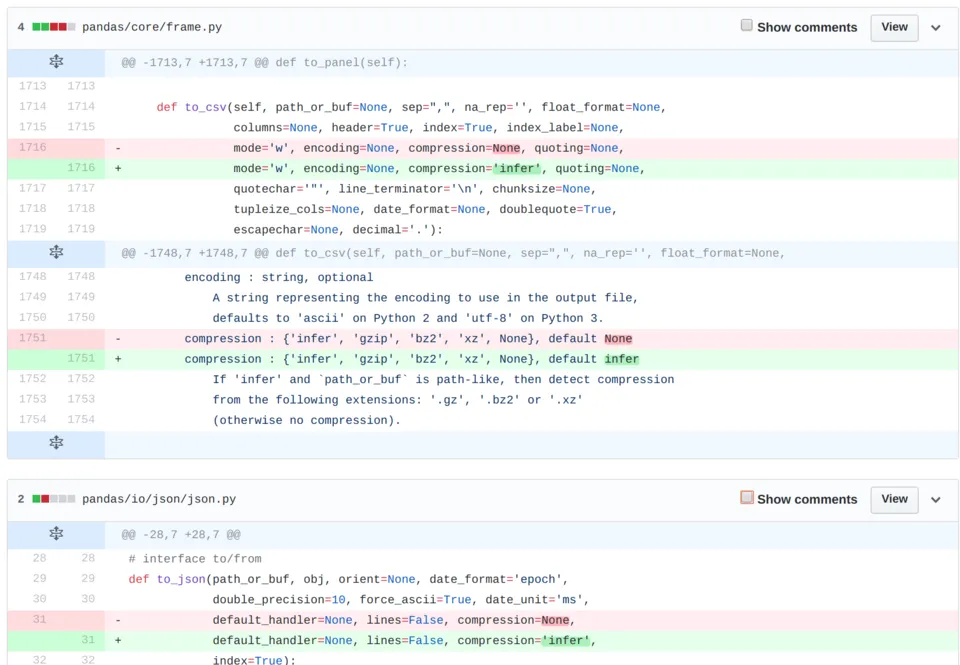
Deceptively simple in fact. One reviewer requested tests, which I thought was a bit excessive since I was just changing the default value for methods where all the possible values should already be tested. The tests ended up coming in handy however since they caught that I hadn't changed the default for Series.to_csv.
A less straightforward issue occurred where one of the Python 2.7 builds was failing, for a reason that made no sense. The test was expecting a RuntimeWarning, which should not have been affected by updating the default. More confusingly, the test picked up the expected warning in Python 3 but not 2! With help from another contributor, we tracked the issue back to a pytest bug where a prior warning elsewhere in a build causes with pytest.warns to fail to detect subsequent warnings. It turned out there was both a pytest bug and a Pandas bug, which began causing warnings in previous tests due to my PR. Once I fixed the Pandas bug, the pytest bug was no longer triggered:
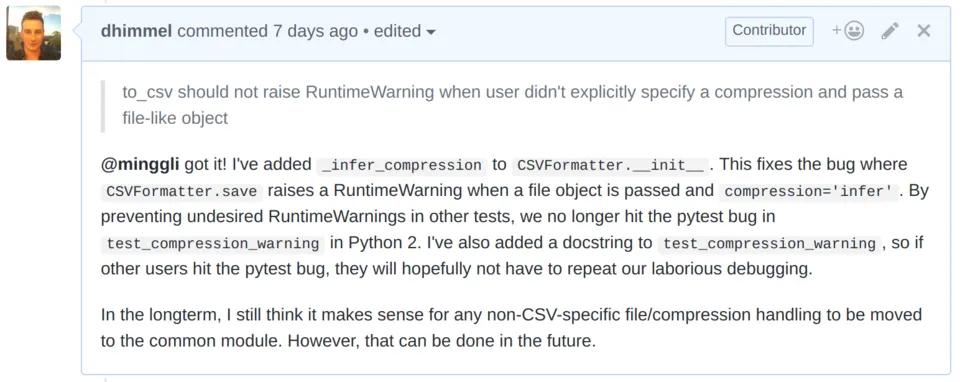
However, the PR did not end here. Various maintainers made additional requests only tangentially related to the specific scope of the PR. For example, I was instructed to move several tests to a more appropriate directory. I also took the opportunity to touch up some aspects of the codebase that could use improvement. Since Pandas has had such a long history with so many contributors, much of the code is less than ideal. Therefore, if I see an easy way to improve code that I'm touching, I think it makes sense to take the opportunity.
When all was said and done, my PR changed 10 files, added 180 lines while deleting 125, and consisted of 40 commits. It was squash merged into pandas-dev/pandas@93f154c. At times it was frustrating how long the pull request dragged on, especially since I went into it thinking it'd be as simple as flipping a switch. However, knowing that soon (as of version 0.24.0) automatic compression will be saving thousands of users time every day provided motivation to continue!
In conclusion, the following is now possible:
# path-to-file.csv.xz will be xz compressed
dataframe.to_csv('path-to-file.csv.xz')
# path-to-file.json.gz will be gz compressed
dataframe.to_json('path-to-file.json.gz')